


在性能测试过程中,发现 CPU 占用非常高,逐步排查是否存在其他瓶
一、 确认 CPU100%是否由I/O等待(%wa)引起
使用 top 或 mpstat 查看 CPU 使用分布:
top
mpstat -P ALL 1 # 每1秒刷新,查看所有CPU核心关键指标:
%wa(I/O Wait):CPU 等待磁盘 I/O 的时间占比。%wa > 10%可能表示磁盘瓶颈。%wa接近 0% 说明 CPU 100% 由计算任务(如代码死循环)引起,而非磁盘
平均时间: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
平均时间: all 4.85 0.00 2.29 7.16 0.25 0.24 0.00 0.00 0.00 85.22
平均时间: 0 6.06 0.00 1.52 0.00 0.51 1.01 0.00 0.00 0.00 90.91
平均时间: 1 5.58 0.00 4.57 0.00 0.00 0.51 0.00 0.00 0.00 89.34
平均时间: 2 6.06 0.00 3.03 0.00 0.51 0.51 0.00 0.00 0.00 89.90
平均时间: 3 5.56 0.00 5.56 9.09 0.51 0.51 0.00 0.00 0.00 78.79
平均时间: 4 8.12 0.00 2.54 15.74 0.51 0.00 0.00 0.00 0.00 73.10
平均时间: 5 5.50 0.00 3.50 35.00 0.50 0.50 0.00 0.00 0.00 55.00
平均时间: 6 8.08 0.00 2.53 25.25 0.00 0.00 0.00 0.00 0.00 64.14
平均时间: 7 6.57 0.00 2.02 23.23 0.51 0.51 0.00 0.00 0.00 67.17
平均时间: 8 19.50 0.00 1.50 0.00 0.00 0.00 0.00 0.00 0.00 79.00
平均时间: 9 2.00 0.00 1.50 0.00 0.00 0.00 0.00 0.00 0.00 96.50
平均时间: 10 3.03 0.00 2.53 0.00 0.00 0.00 0.00 0.00 0.00 94.44
平均时间: 11 2.01 0.00 1.51 18.59 0.00 0.50 0.00 0.00 0.00 77.39
平均时间: 12 2.53 0.00 1.01 15.66 0.00 0.00 0.00 0.00 0.00 80.81
平均时间: 13 1.00 0.00 0.50 11.44 0.00 0.00 0.00 0.00 0.00 87.06
平均时间: 14 0.51 0.00 0.00 2.02 0.00 0.00 0.00 0.00 0.00 97.47
平均时间: 15 1.99 0.00 3.48 2.49 0.00 0.00 0.00 0.00 0.00 92.04
平均时间: 16 4.00 0.00 5.00 0.00 0.50 0.50 0.00 0.00 0.00 90.00
平均时间: 17 3.52 0.00 4.02 10.55 0.00 0.50 0.00 0.00 0.00 81.41
平均时间: 18 1.52 0.00 2.03 0.00 0.00 0.51 0.00 0.00 0.00 95.94
平均时间: 19 4.52 0.00 3.02 1.51 0.50 0.50 0.00 0.00 0.00 89.95
平均时间: 20 5.56 0.00 3.54 0.51 0.51 0.00 0.00 0.00 0.00 89.90
平均时间: 21 4.98 0.00 1.99 14.43 0.50 0.50 0.00 0.00 0.00 77.61
平均时间: 22 6.97 0.00 3.48 2.49 0.50 0.00 0.00 0.00 0.00 86.57
平均时间: 23 3.50 0.00 2.50 0.00 0.50 0.00 0.00 0.00 0.00 93.50
平均时间: 24 1.51 0.00 1.51 2.01 0.00 0.00 0.00 0.00 0.00 94.97
平均时间: 25 9.60 0.00 1.52 11.62 0.00 0.00 0.00 0.00 0.00 77.27
平均时间: 26 6.93 0.00 0.99 4.46 0.50 0.00 0.00 0.00 0.00 87.13
平均时间: 27 2.02 0.00 1.01 9.09 0.51 0.00 0.00 0.00 0.00 87.37
平均时间: 28 1.51 0.00 2.51 13.07 0.00 0.50 0.00 0.00 0.00 82.41
平均时间: 29 2.00 0.00 1.00 0.00 0.50 0.00 0.00 0.00 0.00 96.50
平均时间: 30 5.50 0.00 0.50 1.00 0.50 0.00 0.00 0.00 0.00 92.50
平均时间: 31 7.43 0.00 1.49 0.00 0.00 0.50 0.00 0.00 0.00 90.59列名 含义
CPU CPU 编号,all 表示所有核心的平均值,0、1 等表示具体核心编号。
%usr 用户态程序(非特权)占用的 CPU 时间百分比(如应用程序、Shell 命令)。
%nice 低优先级(nice 调整过)的用户态程序占用的 CPU 时间百分比。
%sys 内核态程序(特权)占用的 CPU 时间百分比(如系统调用、中断处理)。
%iowait CPU 等待 I/O 操作(磁盘/网络)完成的时间百分比。高值可能表示 I/O 瓶颈。
%irq 处理硬件中断占用的 CPU 时间百分比。
%soft 处理软件中断(如网络协议栈)占用的 CPU 时间百分比。
%steal 虚拟机环境下被其他虚拟机偷取的 CPU 时间百分比(仅虚拟化场景)。
%guest 运行虚拟机占用的 CPU 时间百分比(已废弃,现代统计工具通常为 0)。
%gnice 低优先级的虚拟机占用的 CPU 时间百分比(极少使用)。
%idle CPU 空闲时间百分比。低值表示 CPU 繁忙。1. 关键指标分析
整体负载(
all行):%iowait=8.42%:较高,说明系统存在 I/O 等待(需结合磁盘 I/O 统计,如
iostat)。%usr=6.35% + %sys=2.64%:用户态和内核态总占比约 9%,CPU 计算压力不大。
%idle=82%:CPU 整体较空闲,但 I/O 可能是瓶颈。
单核负载不均:
CPU 5:
%iowait=50.51%,%idle=42.42%,说明该核心大量时间在等待 I/O,可能是磁盘瓶颈的焦点。CPU 8:
%usr=38%,%idle=60%,用户态负载较高,可能某个单线程应用在占用该核心。CPU 25:
%usr=18.37% + %iowait=21.43%,计算和 I/O 混合负载。
I/O 瓶颈信号:
多个核心的
%iowait较高(如 CPU 5、12、17、28),需检查磁盘性能(如iostat中的%util和await)。
中断处理:
%soft=0.25%(整体):软件中断占比低,网络或调度压力较小。
%irq=0.35%(整体):硬件中断处理正常,无显著外设压力。
虚拟化影响:
%steal=0%:无虚拟机资源争抢问题。
2.示例结论
主要问题:I/O 等待(
%iowait)较高,尤其是 CPU 5,可能因磁盘速度不足或频繁 I/O 请求导致。次要问题:CPU 8 的单核高负载(
%usr=38%),需检查是否有单线程应用未充分利用多核。建议操作:优先优化磁盘 I/O(如调整文件系统、更换硬件),再分析 CPU 8 的进程分布。
3.CPU 瓶颈的原因
核心问题:应用程序的计算任务(用户态代码)占用了几乎所有 CPU 资源,而非磁盘 I/O 或内核态任务。
可能场景:
高并发计算任务:如数据处理、加密解密、编译等。
代码效率问题:死循环、未优化的算法(如 O(n²) 复杂度)、正则表达式灾难。
数据库负载:未优化的 SQL 查询、全表扫描、缺少索引。
虚拟机 / 容器争抢 CPU:如 Kubernetes Pod 未设置资源限。
4.如何具体定位
top -c -o %CPU # 按 CPU 使用率排
htop # 更直观的交互式工示例图:
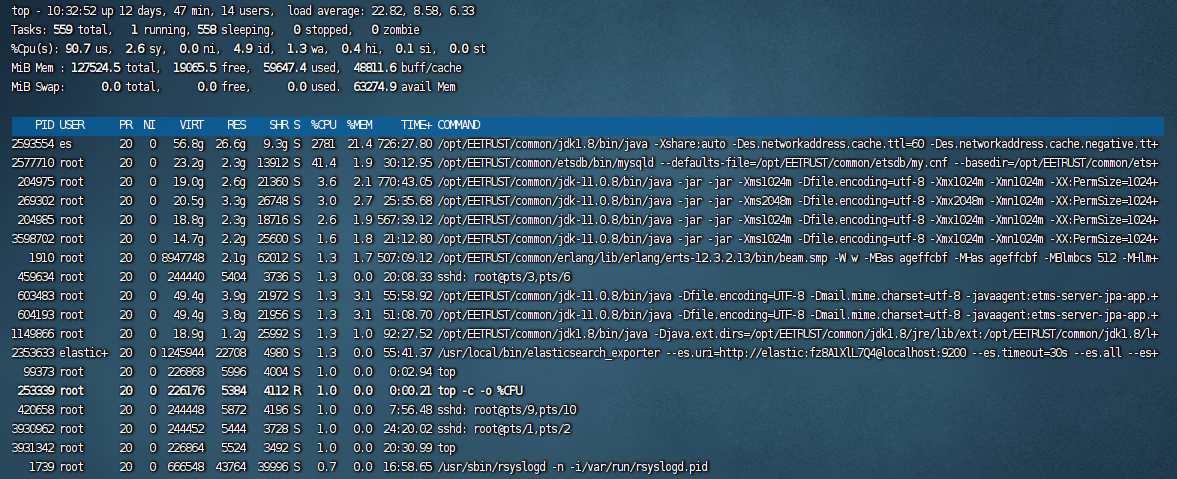
重点关注:
%CPU列:占用高的进程(如 Java、Python、MySQL、ES)。COMMAND列:进程名称或命令行参数。
使用 pidstat 查看线程级 CPU 使用使用 pidstat 查看线程级 CPU 使用
pidstat -t 1 # 每1秒刷新线程统
如果是 Java 进程:生成线程转
jstack <PID> > thread_dump.log # 导出 Java 线程二、定位磁盘 I/O 影响
1.首先使用命令查询磁盘繁忙度,排除是否是磁盘瓶:
iostat -x 1 或 iostat -d -x -k 1 100 # 查看磁盘 util/await
iotop -o # 查看进程
sudo iotop -o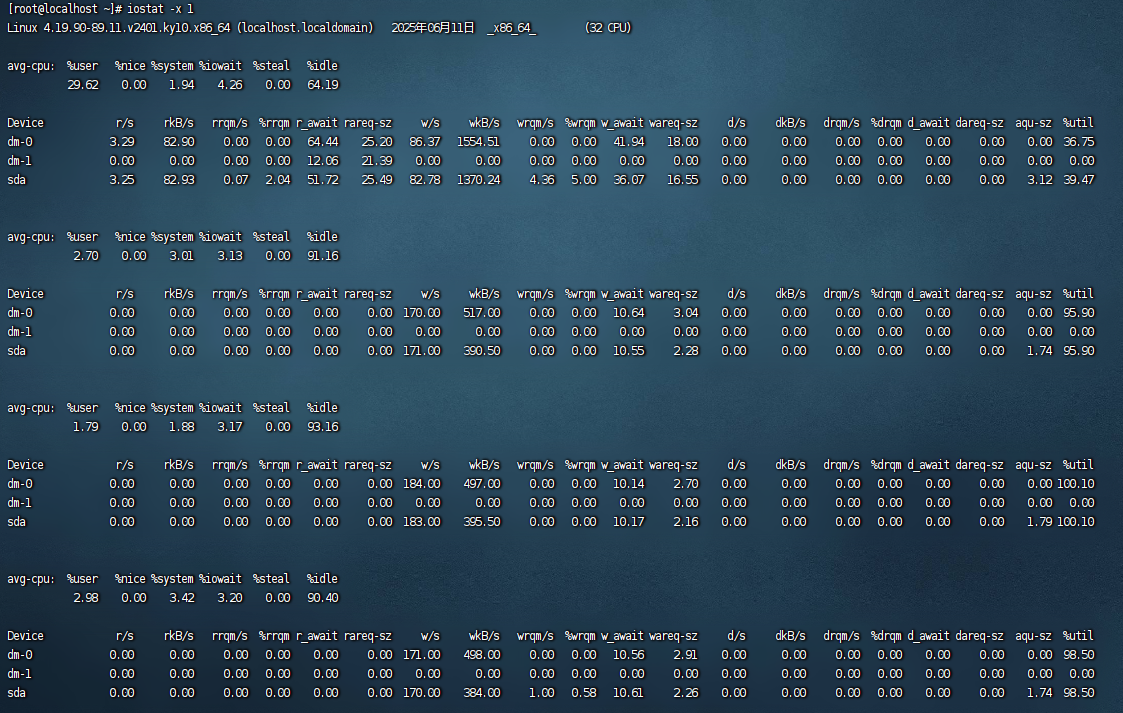
示意:
Device: 设备名称(如 dm-0, sda, sdb 等)。
r/s: 每秒完成的读请求数(read I/O operations per second)。
rkB/s: 每秒从设备读取的数据量(KB/s)。
rrqm/s: 每秒合并到设备队列的读请求数(read requests merged per second)。
%rrqm: 读请求合并的百分比(percentage of read requests merged before being sent to the device)。
r_await: 读请求的平均等待时间(milliseconds),包括队列时间和服务时间。
rareq-sz: 读请求的平均大小(KB)。
w/s: 每秒完成的写请求数(write I/O operations per second)。
wkB/s: 每秒写入设备的数据量(KB/s)。
wrqm/s: 每秒合并到设备队列的写请求数(write requests merged per second)。
%wrqm: 写请求合并的百分比(percentage of write requests merged before being sent to the device)。
w_await: 写请求的平均等待时间(milliseconds),包括队列时间和服务时间。
wareq-sz: 写请求的平均大小(KB)。
d/s: 每秒完成的 discard(丢弃)请求数(discard operations per second)。
dkB/s: 每秒 discard 的数据量(KB/s)。
drqm/s: 每秒合并到设备队列的 discard 请求数(discard requests merged per second)。
%drqm: discard 请求合并的百分比。
d_await: discard 请求的平均等待时间(milliseconds)。
dareq-sz: discard 请求的平均大小(KB)。
aqu-sz: 平均请求队列长度(average queue length of requests)。
%util: 设备的 I/O 利用率(percentage of time the device was busy processing requests)。接近 100% 表示设备饱和。2.关键指标解读:
%util:
表示设备的繁忙程度,接近 100% 表示设备可能成为瓶颈。
例如,
sda的%util在 74.95% ~ 102.90% 之间波动,说明 I/O 压力较大。
r_await / w_await:
较高的
r_await或w_await可能表示设备响应慢或队列堆积。例如,
sdb的w_await高达 1339.00 ms,说明写延迟非常高。
rareq-sz / wareq-sz:
表示 I/O 请求的平均大小,较小的值可能表示随机 I/O,较大的值表示顺序 I/O。
例如,
dm-0的wareq-sz从 16.91 KB 增加到 114.51 KB,说明写请求变大。
aqu-sz:
平均队列长度,值较高表示 I/O 请求堆积。
例如,
sda的aqu-sz在 5.83 ~ 12.00 之间,说明有一定程度的排队。
3.示例分析(以第一段 sdb 为例):
w/s=1.00, wkB/s=124.00, w_await=557.00:
每秒 1 次写请求,平均每次写 124 KB,但平均等待时间高达 557 ms,说明
sdb的写入性能较差。
4.初步分析
在 iostat 的输出中,%util(百分比利用率) 表示设备在统计时间段内的繁忙程度,即设备用于处理 I/O 请求的时间占比。它的计算方式是设备处理 I/O 请求的时间除以总时间,dm-0 和 sda 的 %util 多次达到 97%~99%,说明磁盘 I/O 负载极高,主要来自 写入操作(wkB/s 较高)。以下是排查方法:
5.使用 iotop 查看实时 I/O 占用最高的进程
sudo iotop -oP-o:只显示有 I/O 活动的进程。
-P:只显示进程(不显示线程)。
按 IO% 排序,找到占用最高的进程(如 MySQL、ES、日志服务等)。
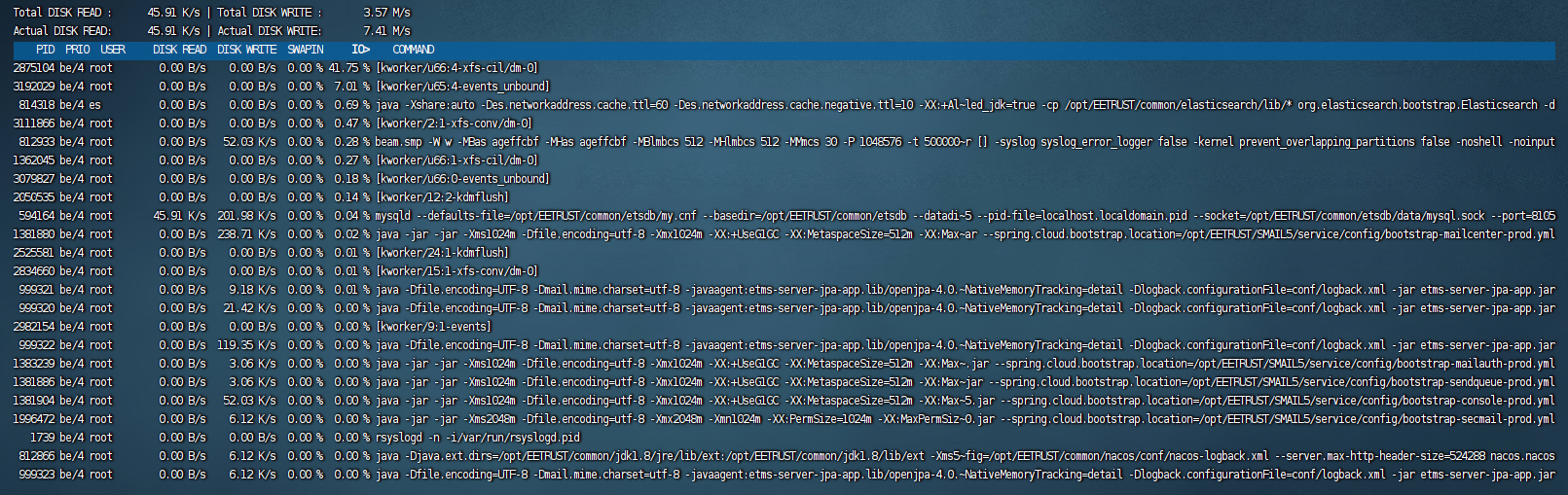
含义:
列名 含义
Total DISK READ 系统全局的磁盘读取速度(K/s 或 M/s)。
Total DISK WRITE 系统全局的磁盘写入速度(K/s 或 M/s)。
Actual DISK READ 实际物理磁盘读取速度(可能排除缓存影响)。
Actual DISK WRITE 实际物理磁盘写入速度(可能排除缓存影响)。
PID 进程 ID。
PRIO 进程 I/O 优先级:be/4(普通优先级),?dif(可能为实时或高优先级)。
USER 进程所属用户。
DISK READ 该进程的磁盘读取速度(B/s、K/s、M/s)。
DISK WRITE 该进程的磁盘写入速度(B/s、K/s、M/s)。
SWAPIN 进程因等待交换内存(Swap)而阻塞的时间百分比(高值可能表示内存不足)。
IO> 进程的 I/O 占用百分比(关键指标,高值表示该进程是 I/O 瓶颈的源头)。
COMMAND 进程名称或命令行参数(可能被截断)。关键分析点
全局磁盘负载:
写入负载较高:
Total DISK WRITE=3.57 M/s,但Actual DISK WRITE=7.41 K/s,说明部分写入可能被缓存(如文件系统缓存)。读取负载低:
Total DISK READ=45.91 K/s,系统主要压力在写入。
高 I/O 进程:
PID 814318(Java/Elasticsearch):
IO>=0.49%,虽然不高,但需结合 Elasticsearch 的日志和配置检查是否在频繁写入索引。
PID 594164(MySQL):
DISK WRITE=422.69 K/s,可能是事务日志(binlog)或数据写入,需检查数据库负载。
PID 1381880(Java 邮件服务):
DISK WRITE=491.07 K/s,写入量较大,可能是邮件附件或日志。
I/O 优先级(PRIO):
大部分进程为
be/4(Best Effort/ 普通优先级),但 Elasticsearch 进程为?dif,可能被调整过优先级。
SWAPIN 列:
所有进程的
SWAPIN=0%,说明无内存交换压力,物理内存充足。
潜在问题进程:
PID 812933(beam.smp):Erlang 虚拟机进程,
DISK WRITE=6.22 K/s,需检查是否与消息队列(如 RabbitMQ)相关。PID 1739(rsyslogd):日志服务,持续小量写入(
3.11 K/s),正常但需监控日志量激增。
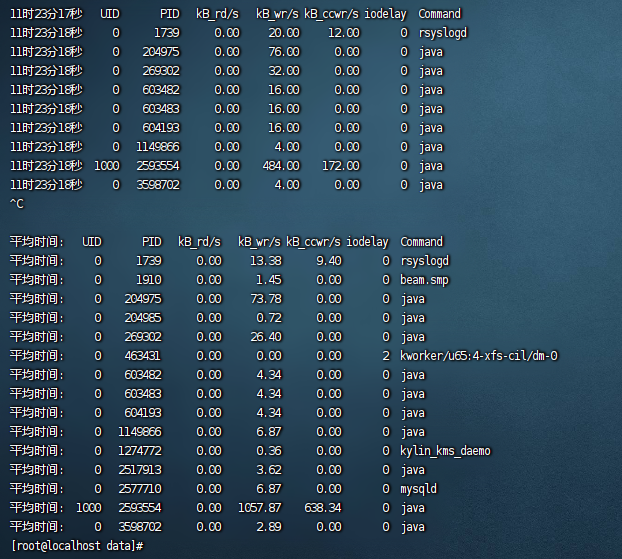
6.使用 pidstat 监控进程级 I/O
pidstat -d 1-d:监控磁盘 I/O。
1:每秒刷新一次。
查看
kB_wr/s(写入速率)和%wait(I/O 等待时间)。
关键指标:
如果某个进程的
kB_wr/s很高(如 >1MB/s),可能就是罪魁祸首。
7. 结合 lsof 查看进程打开的文件
如果发现某个进程 I/O 高,但不确定它在写什么,使用 sudo lsof -p <PID> | grep -i "write" 查看该进程正在写入哪些文件(如数据库文件、日志文件等)。
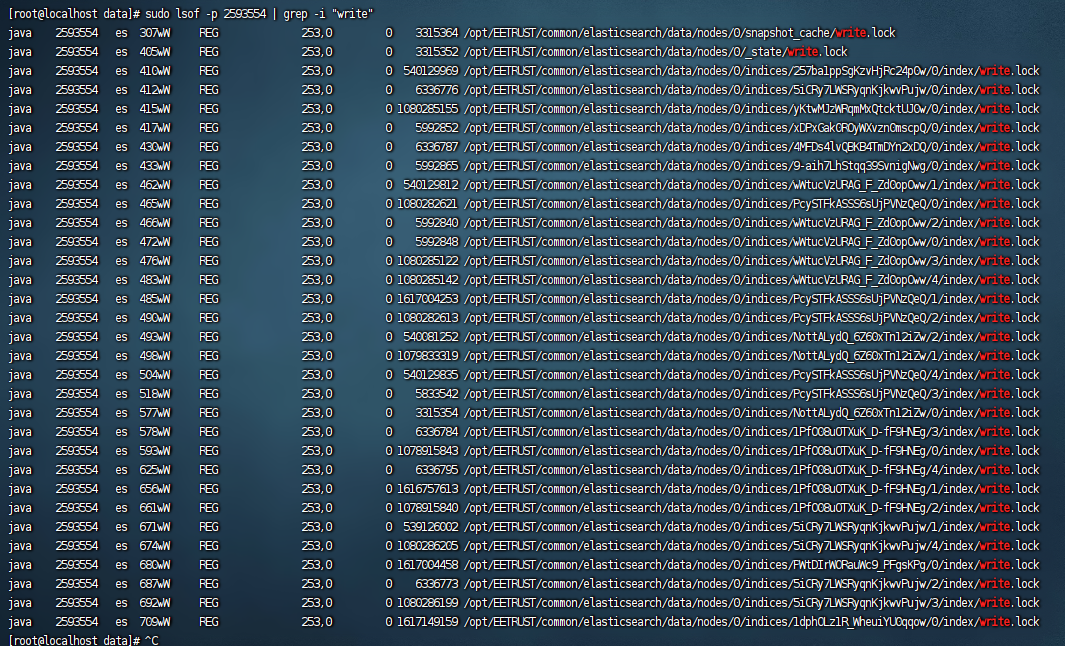
8. 检查 MySQL / Elasticsearch 写入情况
(1)如果是 MySQL
# 查看当前活跃查询(可能有大事务或慢查询)
sudo mysql -uroot -p -e "SHOW FULL PROCESSLIST;"
# 查看 InnoDB 状态(关注 "BUFFER POOL AND MEMORY" 和 "ROW OPERATIONS")
sudo mysql -uroot -p -e "SHOW ENGINE INNODB STATUS\G"如果 Innodb_rows_updated 或 Innodb_buffer_pool_pages_dirty 很高,说明 MySQL 在大量写入。
(2)如果是 Elasticsearch
# 查看索引写入情况(`indexing.index_total`)
curl -XGET "localhost:9200/_nodes/stats/indices?pretty" | grep -A 10 "indexing"
# 查看段合并情况(`merges.current` 高表示正在合并)
curl -XGET "localhost:9200/_cat/segments?v"如果 merges.current 很高,可能是段合并导致高 I/O。
9.关键指标分析
含义:
%util接近 100% 表示设备持续处理 I/O 请求,可能成为性能瓶颈。低百分比(如 10%)表示设备大部分时间空闲。
你的数据解读:
dm-0(LVM 逻辑卷):第一组数据:
%util = 36.66%→ 中等负载。后续几组:
80.60%、81.10%、73.00%→ 高负载,可能需优化。
sda(物理磁盘):第一组:
39.38%→ 中等负载。后续几组:
86.00%、81.20%、73.00%→ 持续高负载,可能是瓶颈。
dm-1:始终0%,表示无活动。
结合其他指标:
高
%util时,需检查aqu-sz(平均队列长度)和await(I/O 平均等待时间):若
aqu-sz高且await高,说明请求积压,设备饱和。你的数据中
await较低(如w_await ≈ 10-20ms),即使%util高,实际延迟尚可。
注意:
对于 SSD 或 RAID,高
%util不一定直接等同于性能问题(因并行处理能力更强)。需结合吞吐量(
rkB/s/wkB/s)和延迟(await)综合判断。
10.结论
最后几组数据的 %util 显示 dm-0 和 sda 处于高负载状态(70%~86%),但延迟较低,可能尚未达到严重瓶颈。建议持续监控,若 %util 持续接近 100% 且延迟上升,则需要优化 I/O(如分散负载、升级硬件)。
三、总结:如何判断 CPU 100% 是否由磁盘引起?
综合分析发现 CPU 占用、磁盘繁忙度都较高,但使用mpstat -P ALL 1 命验证 CPU 资源占用过高并非因等待磁盘引起
磁盘优化:调整日志级别,调整 ES 读写方式,刷盘频率
CPU 优化:mysql 查询索引问题,ES 查询索引问题
评论区